Contents:
- The current state of the Enterprise Storage market: Pricing and Budget Impact.
- Disk Drives: Characteristics and Evolution.
- The early view.
- The Gap: Then and Now.
- A little production theory: Why "popular" drives are much cheaper.
- Further Questions
Robin Harris of "StorageMojo" in "Google File System Eval", June 13th, 2006, neatly summaries my thoughts/feelings:
As regular readers know, I believe that the current model of enterprise storage is badly broken.Not discussed in this document is The Elephant in the Room, or the new Disruptive Technology:Enterprise Flash Memory or SSD (Solid State Disk). It offers (near) "zero latency" access and random I/O performance 20-50 times cheaper than "Tier 1" Enterprise Storage arrays.
Excellent presentations by Jim Gray about the fundamental changes in Storage are available on-line:
- 2006 "Flash is good": "Flash is Disk, Disk is Tape, Tape is dead".
- 2002 "Storage Bricks". Don't ship tapes or even disks. Courier whole fileservers, it's cheaper, faster and more reliable.
The current state of the Enterprise Storage market: Pricing and Budget Impact.
- The promise inherent in the first RAID paper's title (Inexpensive Disks) doesn't seem to be met.
- Are there other challenges, limits or oddities?
A new entrant, Coraid, talking-up the benefits of its solution lays out some disturbing statistics:
With storage cost consuming 25% to 45% of IT budgets ... (ours) offer up to a 5-8x price-performance advantage over legacy Fibre Channel and iSCSI solutions.Vendor Gross Margins
A commentary on one of the 6-7 dominant players (EMC, IBM, Network Appliance, Hewlett-Packard, Hitachi Data Systems, Dell, SUN/Oracle) who control 70-80% of the market by revenue: [compare to gross margins on Intel servers of 20-30%]:
Committing to massive disruption of the storage and networking businesses by moving to 40% gross margins from the current 60+% range through the use of volume and scale out technologies, open source software and targeted innovation leveraging the latest technology.
Can HP compete with 40% gross margins? Well, Apple has done pretty well. [Apple is known for 'premium pricing' and the best returns in the industry.]A large, mature market
The market is large and growing, according to IDG:
... end-user spending on enterprise storage systems reached $30.8 billion in 2010, and the 18% growth over 2009 was the highest since IDC started tracking the market in 1993.Poor utilisation of raw disk capacity?
The enterprise storage systems market will grow at a comfortable 3.9% compound annual growth rate (CAGR) between 2010 and 2015 ...
IBM, touting the benefits of it's XIV Storage, claims massive waste by others' systems:
Overall, we find that the reliability attributes of the system limit the net capacity of a system to 46%-84% depending, for the most part, on the RAID configuration. [46% for a RAID-1 (mirror) config. 84% for RAID-5 (parity/check disk)]
Overall, we see that, by virtue of its built-in efficiency, the XIV system uses 100% of its net capacity, compared with an estimated 28-61% net capacity used by comparable systems. [IBM list 3 types of "wasted space": Orphaned/Unreclaimable Space, Full Backups, Thick Provisioning. Clones and Backups are replaced by 'snapshots' in XIV. IBM neglect filesystem/database 'slack space' within allocated storage.]
The combined effect of the reliability and efficiency attributes is such that, on average, a traditional storage system using mirroring effectively uses less than 21% of its raw capacity (37% when using RAID-5). An XIV system uses approximately 46% of its raw capacity.In the absence of good Operational Expenditure [OpEx] data, a guess
There is speculation that the Operational costs of 'Tier 1' (high-performance, high-availability, most expensive) storage is very high, but no good figures are available [Compare this recurrent cost to the retail price of 1TB SATA disks of ~$100, while fast, durable SAS drives, e.g. 146-160GB, are $200-300, 300-600GB are ~$400]:
With an estimated cost of Tier 1 storage at around $8,000 per TB per year,Indirect Total Cost of Ownership [TCO] estimates
Hitachi Data Systems lays out the costs ownership and product conversion/data migration when pushing the benefits of their "virtual storage" architecture:
Forrester 2007 research has shown that in excess of 70 percent of enterprise IT budgets is devoted to maintaining existing infrastructure.
Migration project expenditures are on average 200 percent of the acquisition cost of enterprise storage.
With an average of four years useful life, the annual operating expenses associated to migration represent ~50 percent of acquisition cost.
Current admin challenges
- Enterprise storage migration costs can exceed US$15,000 per terabyte migrated. [implying 2007(?) acquisition cost of $7,500/Tb.]
- For example, an average FORTUNE 1000® company has an average of 800TB of network attached storage (NAS) and nearly 3PB of storage (InfoPro Wave 12-Q2, 2009) with, on average, 300TB per storage system
- As the useful life of most storage systems is three to five years, ...
The size and complexity of current Enterprise Storage solutions, and the resulting administrator workload, has provoked comments along the lines quoted below. System complexity increases combinatorially as additional layers are added and heterogeneous systems and networks are interfaced. This increases admin workload, task difficultly and execution times, consequentially increasing preventable faults and errors.
Today, storage is the single most complex and expensive component in the virtualized data center.How do Enterprises choose between Vendors and Products?
Many commentators assert that Storage is bought on a single metric: Price per GB.
Comparing other important performance metrics, {latency, IO/second, throughput MB/sec} for "random" and "sequential" I/O workloads is being addressed by the Storage Performance Council, with their SPC1 and SPC2 specifications. For those vendors who choose to participate and publish data on their systems, it provides an "Apples and Apples" comparison for potential customers: including system pricing and discount information.
But there's a problem: system price unrelated to cost of drives.
Overwhelmingly, the price of the raw disk drives is an almost insignificant fraction of the purchase price of "Tier 1" Storage arrays. Competitors claim that the dominant players price their disks up to 30 times the normal retail price, hiding the true cost of the infrastructure wrapped around the drives. Vendors often load special firmware in their drives to prevent substitution. [SPC1 and SPC2 detailed pricing confirms published retail prices of $1-2,000 per drive, 5-20 times retail prices.]
This pricing practice distorts customer system specifications by purchasing far fewer drives, creating additional administrative work in managing allocated disk space and achieving target performance levels.
What is missing is good data on: Price / GB-available-to-Applications.
[Ignoring all the other overheads and "slack space" for Logical Volume Managers and Operating Systems
With Enterprise Storage systems, this is at least 50-100 times the raw cost of drives.
The lesson: Optimising the utilisation of the cheapest and paradoxically least available resource in a system is poor practice.
Meanwhile, there are significant technical and performance issues looming in the world of Enterprise Storage:
- In Triple Parity RAID and Beyond, Adam Leventhal, ACM Queue, Dec 2009, suggests that by 2020 three parity drives will be needed to achieve a 99.2% probability of a successful RAID rebuild recovering from a single drive failure. Multi-parity drives introduce new problems:
- increases Price per GB (more drives for same capacity),
- reduces write performance (1P = 4 IO, 2P = 6 IO, 3P = 8 IO, NP = 2*(N+1) IO)
- increases compute intensity for parity calculations (1P uses trivial 'XOR')
- increases system complexity in efforts to compensate for performance, such as delayed parity writes and caching.
- system robustness and durability is adversely affected by increased component count and software complexity.
- RAID rebuilds severely affect access times and throughput and now take from 3-24 hours, up from "minutes" in the first systems. Documented in "Comparison Test: Storage Vendor Drive Rebuild Times and Application Performance Implications", Feb 18, 2009, Dennis Martin. There are anecdotal reports of RAID rebuilds taking up to a week, degrading performance of all tasks and leaving organisations with protected data for the duration.
[Top]
Disk Drives: Characteristics and Evolution.
- The architecture and organisation of Enterprise Storage Systems are driven by Usage demands and the underlying storage components.
- What's gone before and what might becoming?
But starting about 1989, disk densities began to double each year. Rather than going slower than Moore's Law, they grew faster. Moore's Law is something like 60 per-cent a year, and disk densities improved 100 percent per year.The definitive paper on the limits and evolution of hard disk technology, including a comparison with a dozen other prospective technologies, by Mark Kryder :
Today disk-capacity growth continues at this blistering rate, maybe a little slower. But disk access, which is to say, "Move the disk arm to the right cylinder and rotate the disk to the right block," has improved about tenfold. The rotation speed has gone up from 3,000 to 15,000 RPM, and the access times have gone from 50 milliseconds down to 5 milliseconds. That's a factor of 10. Bandwidth has improved about 40-fold, from 1 megabyte per second to 40 megabytes per second. Access times are improving about 7 to 10 percent per year. Meanwhile, densities have been improving at 100 percent per year.
At the FAST [File and Storage Technologies] conference about a year-and-a-half ago, Mark Kryder of Seagate Research was very apologetic. He said the end is near; we only have a factor of 100 left in density - then the Seagate guys are out of ideas. So this 200-gig disk that you're holding will soon be 20 terabytes, and then the disk guys are out of ideas. [now revised to 14Tb @ $40 for 2.5 inch drive]
"After Hard Drives - What Comes Next?" Kryder and Chang Soo Kim. IEEE Magnetics, Oct 2009.
Assuming HDDs continue to progress at the pace they have in the recent past, in 2020 a two-disk, 2.5-in disk drive [2 platters] will be capable of storing over 14 TB and will cost about $40.In 2005, Scientific American discussed his work and described "Kyrder's Law", in recent years HDD capacity has doubled every year, outstripping Moore's Law for CPU speed.
Given the current 40% compound annual growth rate in areal density, this technology should be in volume production by 2020. [Expect a demonstration in 2015]
Sankar, Gurumurthi and Stan, ICSA 2008, describe the relationship of power consumption to RPM and platter size necessary to understand current drive design [reformatted]:
Since the power consumption of a disk drive isThe external form-factor defines capacity of current HDD's in surprising ways:
proportional to the fifth-power of the platter size,
is cubic with the RPM, and
is linear with the number of platters... [citing a 1990 IEEE paper]
- The 2.5 inch form-factor allows thickness to vary between 7 mm and 19mm, though 19mm is now unusual.
- Compare to the 25.4mm (1 inch) thickness of 3.5" drives.
- Consumer drives, in laptops and PC's, are now normally 9.5mm, with some 7mm. [single platter?]
- Enterprise drives are 15mm, allowing higher capacities by including more platters. [2-3?.
- In 2020, Enterprise 2.5 inch drives will be 2 or 3 platters, hence 14-21TB.
- The maximum platter size is not used in every drive.
- For consumer drives and high-capacity/low-energy Enterprise drives, the largest platters possible are used.
- For high-speed (10,000 [10K] and 15,000 RPM [15K]) drives, the same size platters are used in both 3.5 inch and 2.5 inch drives. This reduces power consumption and seek time through reduced head travel.
- Vendors sell 3.5 inch 15K drives because they can fit more platters in the 25.4 mm vs 15 mm form factor. [4 platters are common, 5 platters are "possible"]
"More than an interface - SCSI vs. ATA", Anderson, Dykes, Riedel, Seagate, FAST 2003.
Last row data from 2004 Patterson address on "Latency and Bandwidth", covering 20+ years evolution of all system components.
1987 2004 times increase CPU Performance 1 MIPS 2,000,000 MIPS 2,000,000 x Memory Size 16 Kbytes 32 Gbytes 2,000,000 x Memory Performance 100 usec 2 nsec 50,000 x Disc Drive Capacity 20 Mbytes 300 Gbytes 15,000 x Disc Drive Performance 60 msec 5.3 msec 11 x Disc Drive Bandwidth 0.6 MB/sec 86 MB/sec 140 x Patterson 2004
Figure 2. Disc drive performance has not kept pace with other components of the
system.
The vendor table omits "transfer rate" or "bandwidth", necessary to calculate the other fundamental characteristic of HDD's, described by Leventhal [ACM Queue 2009], disk "scan time":
By dividing capacity by throughput, we can compute the amount of time required to fully scan or populate a drive.This storage analyst discussion of access density, cost and capacity using SPC benchmarks delves into more fine detail on this and related topics.
RAID array IO/sec performance suffers through the declining access density, which can addressed through higher RPM drives, "short-stroking"/"de-stroking" (using outer 20% of drives) or provisioning the number of drives ('spindles') not on capacity, but desired IO/sec. (Most designers and storage architects would consider this as "over-provisioning" and unnecessarily expensive.)
RAID rebuild times cannot proceed faster than the individual drive scan time, whilst in normal RAID-5 configurations, the total amount of data read for an (ND+1P) parity group, is N-times the drive size. The minimum time taken is (N*Disk-size ÷ common-channel speed), the parity-group scan time, analogous to single-drive scan time. The Networking concept of "over-subscription", the ratio of uplink to total downlink capacity (1:1 is ideal but expensive, higher numbers cause congestion in high-performance environments like server rooms), can be applied to the common-channel and supported drives.
[Top]
The Early View
- Why are we now facing these problems?
- Is this the future that the instigators of RAID foresaw?
Patterson et al describe an application scale-up problem as CPU's speed increases faster than disks and proffer this: "A Solution: Arrays of Inexpensive Disks".
1.2 The Pending I/O Crisisand
What is the impact of improving the performance of some pieces of a problem while leaving others the same? Amdahl's answer is now known as Amdahl's Law...
Suppose that some current applications spend 10% of their time in I/O. Then when computers are 10X faster - according to Bill Joy in just over three years - then Amdahl's Law predicts effective speedup will be only 5X. When we have computers 100X faster - via evolution of uniprocessors or by multiprocessors - this application will be less than 10X faster, wasting 90% of the potential speedup.
In transaction-processing situations using no more than 50% of storage capacity, then the choice is mirrored disks (Level 1). However, if the situation calls for using more than 50% of storage capacity, or for supercomputer applications, or for combined supercomputer applications and transaction processing, then Level 5 looks best.They also suggest that storage arrays will commonly be comprised of very large numbers of disks:
MTTR and thereby increase the MTTF of a large system. For example, a 1000 disk level 5 RAID with a group size of 10 and a few standby spares could have a calculated MTTF of 45 years.But explicitly pose as unsolved questions, just how this might be accomplished:
A further insight into the thinking of these pioneers is found in the Introduction of "RAIDframe: A Rapid Prototyping Tool for RAID Systems" by Courtright, Gibson, et al in 1997. They give a very exact description of how they envision RAID arrays developing [many tiny drives] and why [access time and bandwidth].
- Can information be automatically redistributed over 100 to 1000 disks to reduce contention?
- Will disk controller design limit RAID performance?
- How should 100 to 1000 disks be constructed and physically connected to the processor?
- Where should a RAID be connected to a CPU so as not to limit performance? Memory bus? I/O bus? Cache?
Unfortunately, the 1.3 inch drive by HP (C3014 'Kittyhawk') cited was introduced in early 1992 and discontinued due to slow sales at the end of 1994.
The 1 inch drives they forecast did appear in 1999, the IBM Microdrive, packaged as Compact Flash (CF) cards, and while for a number of years were the largest capacity available in the CF form-factor. They were discontinued in 2006 when Flash Memory overtook them in capacity and Price per GB, never having made it into the Enterprise Storage market.
Wikipedia (Dec 2011) claims that by 2009 all drives smaller than 1.8 inch (used in portable devices) have been discontinued.
Another good source from 1995 is "ISCA'95 Reliable, Parallel Storage Tutorial", Garth Gibson, CMU. Gibson co-authored the original Berkeley RAID paper.
From the "Raidframe" paper:
Further impetus for this trend derived from the fact that smaller-form-factor drives have several inherent advantages over large disks:
These advantages, coupled with very aggressive development efforts necessitated by the highly competitive personal computer market, have caused the gradual demise of the larger drives.
- smaller disk platters and smaller, lighter disk arms yield faster seek operations,
- less mass on each disk platter allows faster rotation,
- smaller platters can be made smoother, allowing the heads to fly lower, which improves storage density,
- lower overall power consumption reduces noise problems.
In 1994, the best price/performance ratio was achieved using 3.5 inch disks, and the 14-inch form factor has all but disappeared.
The trend is toward even smaller form factors:
These tiny disks will enable very large-scale arrays.
- 2.5 inch drives are common in laptop computers [ST9096], and
- 1.3-inch drives are available [HPC3013].
- One-inch-diameter disks should appear on the market by 1995 and should be common by about 1998. [appeared 1999, only achieved commercial success in Digital Cameras]
- At a (conservative) projected recording density in excess of 1-2 GB per square inch [Wood93], one such disk should hold well over 2 GB of data. [got there about 2002]
For example, a one-inch disk might be fabricated for surface-mount, rather than using cables for interconnection as is currently the norm, and thus a single, printed circuit board could easily hold an 80-disk array. [did they mean 8x11in cards? see Gibson's 1995 tutorial, Slide 5/74, for a diagram]
Several such boards could be mounted in a single rack to produce an array containing on the order of 250 disks.
Such an array would store at least 500 GB, and even if disk performance does not improve at all between now and 1998, could service either 12,500 concurrent I/O operations or deliver 1.25-GB-per-second aggregate bandwidth.
The entire system (disks, controller hardware, power supplies, etc.) would fit in a volume the size of a filing cabinet.
To summarize, the inherent advantages of small disks, coupled with their ability to provide very high I/O performance through disk-array technology, leads to the conclusion that storage subsystems are, and will continue to be, constructed from a large number of small disks, rather than from a small number of powerful disks.
[Top]
The Gap: Then and Now.
- Around 25 years on, have the original expectations been met?
- Has the field and technology developed as they envisioned?
- What are the unresolved questions?
Whilst the main thrust of the 1987/8 paper was recommending the use of the smallest disk drives available, at the time 3.5 inch, this was not the practice, especially in commercial systems.
Even in the beginning, vendors and their customers, chose differently, using 5.25 inch drives.
The direct impact on system design was that the Iceberg needed dual-parity to achieve sufficient data-protection, especially for read-errors when rebuilding a RAID parity group after a single-disk failure. The UBER (Unrecoverable Bit Error Rate) of 10 in 10^14 and total parity-group size of 8-16 GB gave an unacceptably high chance of a rebuild failure.
The 5.25 inch drive was the smallest 'enterprise' drive available. The Fujitsu Super Eagle, at 10.5 inches, was discussed in the 1988 paper. At the same time 8 inch SCSI drives were on the market.
In 2005, Herb Sutter wrote a commentary on the end of Moore Law for single-core CPU's "The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software". Early in 2003, CPU's hit a "Heat Wall" limiting the clock-frequency. Whilst more transistors could be placed on a CPU die, the clock-frequency (speed) stalled. To improve CPU throughput, designers placed more cores in each CPU, the equivalent to a network connection using more parallel conductors to increase total bandwidth without increase the speed of an individual connection/conductor.
In contrast to this sudden change, Hard Disk access density has been steadily eroding whole array performance for the last two decades, steadily forcing design changes and increasing complexity.
It's unlikely that when fundamental limits are reached an "IO Performance Wall" will be created for hard disks. Though, like CPU's, some unexpected physical constraint may limit realisable capacities.
The projected maximum areal density of disk drives results in fixed sizes for 2.5 inch and 3.5 inch platters. The Industry Standard form-factors fix the size available, and potentially the number of platters possible in each form factor. With the advent of cheap Flash Memory in SSD's, there is little need for high RPM Hard Drives.
There has been one major form factor conversion, from 5.25 inch to 3.5 inch. Currently 'Tier 1' storage is being sold in both 3.5 inch and 2.5 inch form factors. To understand if 2.5 inch drives will become universal, we need to examine the history of the last conversion and the differences to now.
Slide 25/74, "Disk Diameter Trends", of Garth Gibson's ISCA'95 Reliable, Parallel Storage Tutorial covers these transitions:
Decreasing diameter dominated 1980sIt isn't clear when 5.25 inch drives went out of production and Enterprise storage swapped completely to 3.5 inch drives. Seagate's 10Gb "Elite 9" ST410800N (the ST410800N manual, static URL) was released in 1994. The cut-over time will have been before the product's end-of-life in 1997/8.
* 5.25" created desktop market (16+ GB soon)
* 3.5" created laptop market (4+ GB 1/2 high; 500+ MB 19mm)
* 2.5" dominating laptop market (200+ MB; IBM 720 MB)
* 1.8" creating PCMCIA disk market (80+ MB)
Decreasing diameter trend slowed to a stop
* 1.8" market not 10X 2.5" market
* 1.3" (HP Kittyhawk) discontinued
* vendors continue work on smaller disks to lower access time
Slide 20/74 of Gibson's 1995 tutorial plots the year of introduction of different drive capacities by drive size. It tracks 5.25 inch drives until 1994 with 10GB introduced, confirming the first estimate.
The reasons will have been complex and many, but at some point all the significant metrics would've favoured 3.5 inch drives and then result was foregone.
Metrics that matter to Enterprise Storage vendors:
- Price per GB
- Both form factors are in high-volume production, with a small premium for 2.5 inch drives.
- Laptops and notebooks have outsold desktop PC's for a number of years, at least balancing demand for 2.5 inch drives.
- GB per cubic-unit (normally per "Rack Unit" (RU) in a "19 inch" rack (1.75 in x 17.75 in x 24-36 in))
- Standard vertical mounting sees 13-16 3.5 inch hot-swap drives in a 3RU space, and
- 24 2.5 inch drives in a 2RU space.
- 4.3-5.3 drives/RU vs 12 drives/RU.
- The ratio of platter area, a close approximation to capacity per platter, is 2:1, making the ratio about 5:6.
- 2.5" drives a 20% higher storage density per platter for a given technology,
- But there extra platters in 25.4 mm vs 15 mm. (50% more platters)
- For high RPM drives with identical capacities, 2.5 inch wins,
- for same-RPM drives, 3.5 inch drives store
- Orienting 3.5 inch drives horizontally, 3-high by 4-wide (12) will fit in 2RU, the best packing is 6/RU.
- Watts per GB and implied operational costs.
- In higher RPM drives, Watts per GB currently is comparable (shown above).
- For 'slow' 7200RPM drives, the fifth-power-law of platter diameter to power consumption means 2.5 inch drives will consume significantly (535%!) less power. (3-4W vs 15W)
- Western Digital now sell a line of 'Green' 3.5 inch drives with variable RPM, reducing power demand considerably.
- Operational costs, e.g. cooling capacity and cost of electricity, over the 5 year service life of equipment (~45,000 hours) may be the deciding factor.
1,000 * 3.5 inch drives will consume ~650,000 kilo-Watt-hours vs 125,000 kWhrs.
At $0.25/kWhr, a lifetime saving of ~$135 per drive.
- Average access time (based on rotational latency and seek times).
- Smaller drives can be spun faster and still consume less power.
[Top]
A little production theory: Why "popular" drives are much cheaper.
Accounting Theory has the concept of the "Learning Curve", also called "Experience Curve".
It originated with Wright in 1936 examining small-scale production and noting that doubling production, reduces costs 10-15%.
Does the Experience Curve scale-up?
If you produce 100,000 times more, (16+ doublings), can you realise these benefits all the way?
- 10%-per-doubling improvement = 18.5% (81.5% cost reduction)
- 15%-per-doubling improvement = 7.5% (92.5% cost reduction)
These plant costs and the product Research and Development costs have to be amortised across all units produced. For fixed and overhead costs to be a small fraction of the per-unit cost, the number of units now has to be very large: 10-100 million.
In 2011, there are forecast to be 400M+ PC's (desktops and laptops) produced. Laptops, using 2.5 inch drives, passed desktops as the most popular format around 5 years ago. These high volume demands underpin the production of both 3.5 inch and 2.5 inch disk drives.
Volume production counts for a lot.
If there isn't already a high demand for a product, the per-unit price will be considerably inflated to cover "sunk costs": everything involved in creating the product.
Once the plant and Research costs are paid for, per-unit costs can be lowered more.
After a time the Price/Capacity of old technology products, even when fully amortised, will be too much higher than new technology and demand will fall away rapidly.
When demand falls and production runs are too small, the plant becomes uneconomic because fixed-costs (operational/production costs) start to overwhelm the per-unit price. Manufacturers must close plants when they start to make losses: the situation can only get worse, rapidly.
As an example, consider the two machines that Seymour Cray designed for Control Data Corporation (CDC) in the 1960's/70's before leaving to create his own company:
- CDC 6600 World's fastest computer: 1964-1969.
- CDC 7600 World's fastest computer: 1969-1975. reputedly $5M (equivalent to $30M now).
The difference between Intel et al and Cray/CDC was volume production.
When you hand-craft 100-1,000 machines, they cost millions.
When you build CPU's by the million, they cost $100-$1,000.
It redefines how you architect and organise super-computers.
This "substitution effect" affects all commodity products.
[Top]
Further Questions
Economics asserts "Price is the Mediator between Supply and Demand".
In a mature, free market, where purchasers have "perfect information" and products are fungible (perfect substitutes for each other), competition will drive prices down (and consumption of goods will increase) and inefficient producers will be driven from the market.
But the Enterprise Storage market has the very high gross margins associated with new markets or non-substitutable products.
Q: What's happening between vendors and purchasers to produce this skewed market?
- Are Enterprise Storage products fungible or not?
- Are secondary effects at work preventing product substitution? [warranty conditions, staff capability, integrated platform management software, decision inertia/product loyalty or technical conservatism.]
- Is the purchasing criteria "Price/GB", I/O performance, (perceived) Reliability/Availability etc, functionality or something else?
Performance (latency and throughput) of HDD-based Enterprise Storage arrays is rated "good enough" in the market because for 10-15 years many new entrants have attempted to break into the market by offering low-cost or high-performance products.
Q: What "figure of merit" do purchases use to chose between vendors and products? Is it "just" price/GB, because it isn't "performance".
- Without extensive customer research, this may be unknowable.
There aren't convincing reasons favouring smaller or larger form-factor drives unless high RPM drives or SSD (packaged in 2.5 inch or 1.8 inch) are included.
Q: Why has the take-up of SSD's in Enterprise environments been slow when the price/performance ratios are so far ahead of 'conventional' Storage systems?
Kryder's Law, the on-going compound increase in HDD size and price/GB has caused some changes in fundamental ratios:
Storage Arrays initially lashed together many small devices into "large enough" logical/virtual devices.
Somewhere in the last 25 years, drive capacity exceeded normal use cases by multiples.
The basic RAID I/O performance drivers for both latency and throughput, many spindles and actuators reduce latency and parallel transfers increase throughput, were invalidated, but the designs seemed not to change.
- 1988: IBM 3380 7.5GB. Databases, Files fitted within this limit.
- RAID from 320MB-1GB, more spindles, more IO/sec, higher throughpu
- RAID from 320MB-1GB, more spindles, more IO/sec, higher throughpu
- 2010: 600GB 10/15K, 2TB SATA drives.
- These units are now (much!) larger than most common Databases and file stores.
- Not just video, images, audio, scanned stuff. MS-Office documents as well.
Q: Why did Storage arrays not respond to this change in fundamental drivers?
- Did the change happen so slowly that nobody noticed?
- Storage vendors are generally very innovative and competitive, employing some of the "best and brightest" in computing.
This wasn't a failure of ability or capability. Perhaps of vision? - Are incumbent vendors locked into their own solutions, leaving innovation to new entrants?
- Did consumers demand products they were familiar and comfortable with and prevent vendor changing designs?
Why didn't large numbers of really small HDD's get tried by major vendors, even as an experiment?
IBM, the leader in 1 inch drives, sold it's drive business to Hitachi Data Systems (HDS), a leading Storage system vendor with expertise in many related areas.
HDS had the capability to create custom packaging, custom electronics (ASIC's) and to redesign the 1 inch drive format (Compact Flash with IDE). For very small drives to be soldered onto boards, a simple, continuous serial interface was needed. SAS, Serial Attached SCSI, would fit the bill today.
In the 3 years before 1 inch HDD's lost their price advantage to Flash memory, HDS could have built a prototype and proven the concept, but (seemingly) didn't. Nor did any academic projects.
Q: Why did the Industry and Academic researchers not build a "many tiny drives" Array between 2000 and 2005?
To show that very low overhead Storage devices can be built outside Google datacentres, these are the full on-line instructions and Bill of Materials for one service providers solution:
"Petabytes on a budget: How to build cheap cloud storage", September 1, 2009
"Petabytes on a Budget v2.0: Revealing More Secrets", July 20, 2011
135TB for $7,384, around 50% more than the raw cost of the drives.A chart in the first piece comparing the Price / GB of different solutions.
{kind=link}
RAW: $81,000 [660 @ 1.5TB ] 45 @ $120 == $5400
backblaze: $117,000 [50% o'head]
Dell MD1000 $826,000
SUN/Ora X4550 $1,000,000
NetApp FAS-6000 $1,714,000
Amazon S3 $2,806,000
EMC NS-960 $2,860,000
Pix of Storage Pod & component costs.
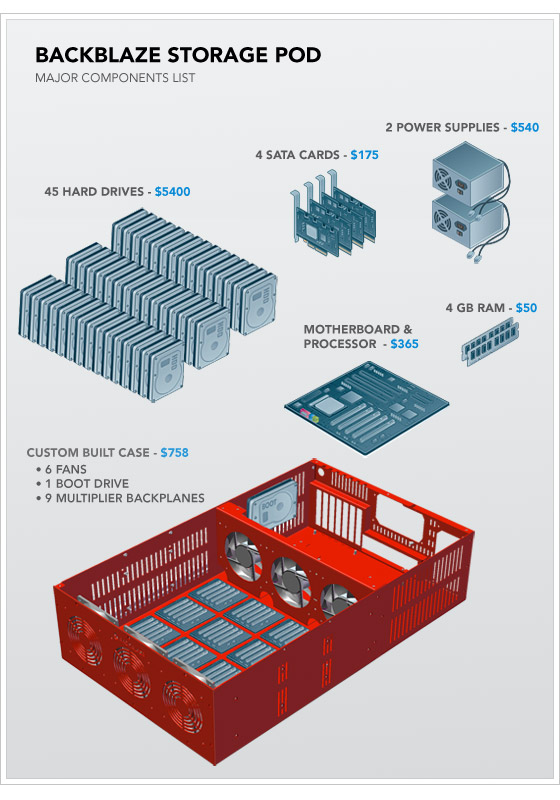{kind=link}
No comments:
Post a Comment